Redis简介
Redis是一个高效的键值对内存数据库。
基本数据结构
简单动态字符串(SDS)、链表、字典、跳跃表、整数集合、压缩列表。基于这些数据结构实现了Redis的5种存储类型,分别是字符串、哈希、列表、有序集合、集合,每种类型底层有多种数据结构实现方法,根据应用场景不同而变化。
SDS
长度可变,当进行扩展时,除了分配所需的空间外,还分配额外的未使用空间,有效减少内存重分配次数,释放时不真正释放,采用惰性释放,用free字段记录这些字节。
字典
用哈希表实现:用链式地址法解决键冲突,具有相同哈希值的键用一个链表存储起来,将新节点添加到链表的头节点位置。
当哈希表的键值对太多或太少时,会进行相应的扩展或收缩,内部有两个哈希结构,记为ht[0]和ht[1],平常只用到ht[0]用来存储键值对,当要扩展时,首先将ht[1]的大小设为第一个大于等于ht[0].used*2的2的n次方,收缩时,将ht[1]的大小设为第一个大于等于ht[0].used的2的n次方,然后将ht[0]里的键值对rehash到ht[1]中,释放ht[0],将ht[0]设为ht[1],ht[1]设为ht[0],并在ht[1]创建一个空哈希表为下一次rehash准备。决定是否要扩展或者收缩根据负载因子(used/size)确定。当键值对非常多,一次rehash会占用相当长的时间,导致服务器停止服务,因此实际上rehash时分多次、渐进式的完成的。具体来说,在字典中维护一个rehashidx变量,从0开始计数,在每次对字典进行查找删除添加的时候,将rehashidx这一索引上的键值对全部rehash到ht[1]中,相当于在每次操作之后rehash一行键值对,然后rehashidx加1,下次操作rehash下一行,如此rehash完所有行后将rehashidx设为-1表示rehash操作已完成。这么做的好处是将所有工作均摊到每一次操作上,避免了一次性rehash的庞大计算。此外,在rehash期间进行的删除查找操作会在两个表上查找,而添加操作一律添加到ht[1]中。
跳跃表
平均O(logn),最坏O(n)的查找。是有序集合的基本数据结构。
整数集合
底层实现是数组,保存整数。数组有个类型,当新加入的数比这个类型长时,数组会进行升级。只有在必要时才进行升级,尽可能节约了内存。
压缩列表
压缩列表节约内存。可以包含多个节点,每个节点保存一个字节数组或者用一个整数值。添加或者删除节点,可能引发连锁更新操作,出现几率并不高。
字符串
底层编码可以是int、raw(SDS)、embstr。embstr是专门保存短字符串的优化编码方式,当字符串长度小于等于39会采用。
命令:set、get、append、incrby、decrby、……
列表
编码可以是压缩列表和双向链表,内部会嵌套字符串对象。当所有字符串长度小于64且元素数量小于512用跳跃表,否则用链表。
命令:lpush、rpush、lrange、lpop、rpop、……
哈希
编码可以是压缩列表和哈希表。转化条件和列表一样。
命令:hset、hget、hexists、hmset、hmget、hgatall……
集合
编码可以是整数集合或者哈希表。当元素都为整数且数目不超过512个用整数集合,否则哈希表。
命令:sadd、smembers、spop……
有序集合
编码可以是压缩列表和跳跃表。字典提供O(1)的查找复杂度,而跳跃表提供快速的范围操作。当元素数量小于128个,且长度都小于64字节时用压缩列表。
命令:zadd、zrange、zrank、zscore……
内存回收
基于引用计数的内存回收。当计数为0释放内存。此外当一个对象同时被两个键引用时,还会进行共享,即对象只有一份,引用计数为2,节约内存。目前Redis会在初始化服务器时创建0到9999的所有整数作为共享对象。
空转时长
对象里还有一个lru属性,记录了对象最后一次被命令访问的时间,当前时间减去lru即时空转时长,空转时长较高的键会被释放,回收内存。
单机数据库
数据库基本数据结构
数据库的结构为redisServer:1
2
3
4
5struct redisServer{
...
redisDb * db; //保存所有的数据库
int dbnum; //数据库的数量
}
默认情况下,数据库有16个,启动时默认选择0号数据库,可以用select命令选择数据库:1
select 2
变化的是客户端数据库,服务器的数据库总是从0开始。
dict字典保存了所有键值对:1
2
3
4
5struct redisServer{
...
dict* dict; //保存所有键值对
dict* expires; //保存所有键的过期时间
}
可以用expire为键设置过期时间,时间到自动删除。expires字典保存了所有键的过期时间,值为longlong,是一个毫秒精度的unix时间戳。persist可以移除一个键的过期时间。对于过期键的删除策略,有以下三种方式:
- 定时删除:设置键过期时间时设置一个定时器,时间到了进行删除。
- 惰性删除:不主动删除,获取键的时候判断是否过期,如果过期再删除。
- 定期删除:每隔一段时间,对数据库进行检查,删除其中的过期键。
定时删除对内存最友好,因为可以第一时间删除过期的键,但是对cpu不友好,每次都需要占用cpu时间,删除时需要处理与当前无关的键。惰性删除是对cpu最友好的,每次只对查询的键做处理,如果过期才删除,同时对内存最不友好,因为存在大量过期的无用的键没有及时删除占用内存。定期删除是一种折中方案,难点是确定删除的时长和频率。Redis使用的是惰性删除和定期删除两种策略。定期删除是在服务器的周期性操作serverCron执行时进行的,每次运行时,从一定数量的数据库中随机取出一定数量的随机键进行检查,删除其中的过期键,每轮检查有一个时间,时间到了则停止检查,记录下此时检查到第几个数据库,下次继续从这个数据库开始检查过期键。
持久化
Redis是内存数据库,数据都存储在内存中,如果服务器退出,内存中的数据就都丢失了,因此需要将数据保存在本地磁盘上,称为持久化。分为RDB持久化和AOF持久化。
RDB持久化
RDB文件是一个经过压缩的二进制文件。save和bgsave命令会生成RDB文件,save会阻塞服务器直到文件写入完成,而bgsave会创建子进程来写文件,服务器能够继续正常运行,子进程完成后向父进程发送信号。服务器启动时自动读取RDB文件恢复数据库内容,读取是阻塞的。通过配置文件的save选项,若一段时间内执行了一定次数的写操作,则服务器可以自动进行bgsave命令来保存RDB文件。RDB文件由5部分组成:
|REDIS|db_version|databases|EOF||check_sum|
对于不同的键值对,会用不同的方式保存。
AOF持久化
RDB文件保存数据库的数据,而AOF文件保存的是服务器执行的写命令。每执行一条写命令,都会添加到AOF文件中,AOF实现可以分为命令追加、文件写入、文件同步三个步骤。服务器结构中有一个AOF缓冲区,命令追加到缓冲区中,Redis默认是每秒将缓冲区中的内容写入文件并进行同步,因为write调用是将内容写入到内核的io缓冲区中并不是马上写入磁盘文件,所以需要同步操作(fsync)来讲io缓冲中的内容写入文件。
AOF载入时,会先创建一个伪客户端,让这个客户端执行AOF文件中的写命令,从而恢复数据库数据。
随着写命令的增加,AOF文件可能变得非常庞大,不利于服务器的运行。Redis提供了AOF重写功能,创建一个新的AOF文件,这个文件的数据库状态和旧文件相同,但是没有冗余的写命令,体积小得多。AOF重写不需要分析现有的AOF文件,它是通过读取服务器状态来实现的。原理是读取数据库所有键目前的值,然后只用一条写命令记录键值对,代替多条命令,因此新AOF文件只包含必要的命令,不会浪费任何空间。
AOF提供了后台重写的功能,创建子进程来重写AOF文件,但是存在一个问题,创建子进程后可能会有新的写命令改变了数据库的状态,导致AOF文件和当前数据库状态不一致,为解决该问题,设置了一个AOF重写缓冲区,创建子进程之后,所有执行的写命令都写到这个缓冲区中,等到子进程完成重写操作向父进程发送信号,父进程将AOF重写缓冲区中的写命令全部写到AOF文件中并同步,如此数据库的状态就一致了。
事件
Redis服务器是一个事件驱动型程序,处理两种事件:文件事件和时间事件。文件事件就是和客户端产生的一些网络事件,时间事件是定时的操作。
Redis基于reactor模式开发了网络事件处理器,处理器采用io复用的方式同时监听多个套接字,根据套接字目前执行的任务来为套接字关联不同的事件处理器,整体是单线程的,保持了Redis内部单线程的简单性。结构如下: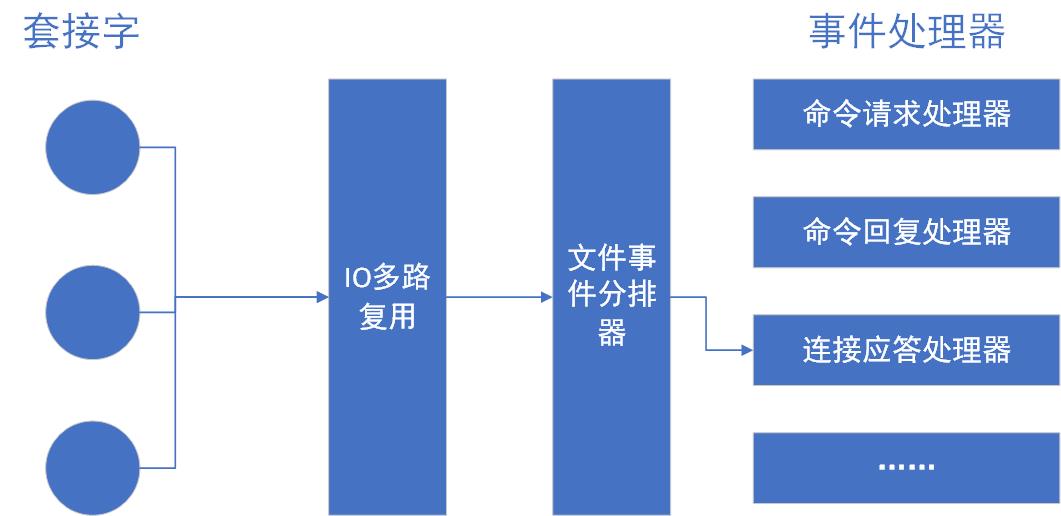
网络事件类型分为可读(客户端发起连接或者write)和可写(客户端read),如果又可读又可写,优先处理可读。最常见的事件处理器是连接应答处理器、命令请求处理器、命令回复处理器。
时间事件分为定时事件、周期性事件。目前Redis只使用周期性事件。服务器将所有的时间事件都放在一个无序链表中,每次时间事件执行器运行时,遍历这个链表查找已经到达的时间事件调用相应的处理器,正常模式下只有serverCron这一个时间事件。
serverCron的主要工作包括:
- 更新服务器的各类统计信息,如时间、内存占用、数据库占用等
- 清理数据库中的过期键值对
- 关闭清理连接失效的客户端
- 尝试进行持久化
- 若服务器是主服务器,对从服务器进行定期同步
- 若处于集群模式,对集群进行定期同步和连接测试
默认每隔100毫秒运行一次serverCron。
服务器事件的调度与执行过程:首先获取距离当前时间最近的时间事件,以这个时间作为io复用的超时时间,然后执行io复用,处理文件事件,然后处理时间事件,伪代码如下:1
2
3
4
5
6def processEvent():
time_event = searchNearestTimer()
time = time_event.when - unix_ts_now()
poll(time)
processFileEvents()
processTimeEvents()
服务器的主函数的伪代码为:1
2
3
4
5
6
7
8
9def main():
# 初始化服务器
init_server()
while server_is_not_shutdown()
processEvent()
# 清理服务器
clean_server()
客户端
客户端包含一些属性,包括:
- 套接字描述符
- 名字
- 标志(记录了客户端的角色和状态)
- 输入缓冲区(保存命令)
- 命令与命令参数
- 命令的实现函数(在命令表中查找对应命令的函数)
- 输出缓冲区(保存回复,2个缓冲区,一个大小固定,保存长度较小的回复,一个大小可变,保存长度长的回复)
- 身份验证
- 创建客户端的时间、客户端与服务器最后一次互动时间、空转时间
服务器用clients链表连接多个客户端,新客户端放到末尾。缓冲区限制分为硬限制和软限制,一旦缓冲区中的数据长度超过硬限制立即关闭该客户端,若超过软限制且在一段时间内一直超过软限制也将其关闭,若一段时间内没有超过软限制了就不关闭该客户端。
服务器
命令请求的执行过程:
- 发送命令请求
- 读取命令请求
- 查找命令实现、执行预备操作、调用命令的实现函数、执行后续工作
- 将命令回复发送给客户端
- 客户端接受并打印回复
serverCron函数默认每隔100毫秒执行一次,负责管理服务器的资源,所做的工作如下:
- 更新服务器的时间缓存,即当前时间
- 更新lru时钟
- 更新服务器每秒执行次数
- 更新服务器内存峰值记录
- 处理sigterm信号
- 管理客户端资源,调用客户端的clientsCron函数,如果客户端已经超时(空转时间太长)就释放它,若输入缓冲区超过一定长度,释放该缓冲区,重新建立一个默认大小的缓冲区,避免占用太多内存
- 管理数据库资源,删除过期键
- 执行被延迟的bgrewriteaof
- 检查持久化操作的运行状态
- 将AOF缓冲区的内容写入文件
- 关闭异步客户端
- 增加cronloops,代表serverCron运行的次数
服务器初始化的过程:
- 初始化服务器状态结构
- 载入配置选项
- 初始化服务器数据结构
- 还原数据库状态
- 执行事件循环
多机数据库
主从复制
通过slaveof命令让一个服务器(从)复制另一个服务器(主),首先从服务器向主服务器发送sync命令,主服务器向从服务器发送RDB文件,并且在缓冲区中记录下之后执行的命令,从服务器读取RDB文件进行数据库恢复,然后主服务器将缓冲区中的命令发送给从服务器使得状态一致。之后每次写命令改变主服务器时,主服务器都会将命令传播给从服务器。但是当从服务器断线,然后重新上线时,为了恢复主服务器的状态,要重新发送sync命令重新生成RDB文件,这非常耗费时间和资源。为解决这个问题,psync命令可以实现部分同步,只需要将从服务器缺少的命令发送给从服务器。部分同步由三个部分组成:
- 复制偏移量,主服务器发送N字节就将自己的复制偏移量加N,从服务器接受N字节就将自己的复制偏移量加N,因此只要主从服务器的复制偏移量不同就说明从服务器掉线了。
- 复制积压缓冲区,时一个固定长度的队列,默认大小1m,缓冲区中记录着最近向从服务器传播的写命令,同时记录了每条命令的偏移量,当从服务器故障恢复时把自己的偏移量offset发送给主服务器,如果offset之后的命令都在缓冲区中,就可以将这部分命令发给从服务器完成部分同步,若不存在则进行完全同步。
- 服务器运行id,运行id在服务器启动时自动生成,由40个随机的十六进制字符组成,从服务器保存主服务器的运行id,当故障重启时,判断当前连接的主服务器的id和保存的id,如果id一致,说明之前就是连接的这个主服务器,则可以尝试进行部分同步,若id不相同,说明现在已经连接到一个新的主服务器,则进行完全同步。
复制的实现步骤:
- 设置主服务器的地址和端口
- 建立套接字连接
- 发送ping命令
- 身份验证
- 发送端口信息
- 同步
- 命令传播
此外还有心跳检测用域检测主从服务器的网络连接状态,检测命令丢失,辅助实现min-slave选项。
sentinel
sentinel(哨兵)系统可以监视多个主服务器以及所有从服务器,当监视的主服务器下线时,会从它的从服务器中选一个成为新的主服务器接管下线的主服务器,当下线的服务器再次上线时,它会成为新的主服务器的从服务器。
snetinel会以每秒一次的频率向所有与他建立连接的实例发送ping命令,当主服务器连续50000毫秒都返回无效回复时,sentinel将其标记为主观下线,为了确认这个服务器是否真的下线,它会向其他监视这个服务器的sentinel进行询问,当它收集到足够多的下线判断后,就将服务器判定为客观下线,并进行故障转移。首先挑选出一个状态良好、数据完整的从服务器升级为主服务器(优先级高,复制偏移量最大),让其他从服务器成为新的主服务器的从服务器,让下线的主服务器成为新的主服务器的从服务器。
集群
集群由多个节点组成,节点通过cluster meet和其他节点连接起来,一个节点就是一个服务器。
集群通过分片的方式保存数据库中的键值对,数据库被分为16384个槽,每个键都属于这些槽中的一个,每个节点可以处理0个到16384个槽。
节点收到一个命令请求时,会先检查这个命令请求的键所在的槽是否指派给自己,如果是就处理,如果不是则返回一个moved错误指引客户端转向负责该槽的节点。
集群里的从节点用于复制主节点,并在主节点下线时,代替主节点继续处理命令请求。(与sentinel类似)。
集群中的节点通过发送消息来通信,包括meet、ping、pong、publish、fail。
发布与订阅
通过subscribe订阅频道,当客户端向该频道发送消息时(publish),所有订阅该频道的客户端都能接收到消息。
在服务器中有一个字典记录了对应频道的所有订阅用户:1
2
3
4struct redisServer{
//...
dict* pubsub_channels;//保存所有频道的订阅关系
}
该字典的键是频道,值是一个链表,链表记录了所有订阅这个频道的客户端。
此外还可以订阅一个模式,相当于订阅了所有与该模式匹配的频道。在服务器中也有一个链表保存所有订阅模式的信息:1
2
3
4struct redisServer{
//...
list* pubsub_patterns;//保存所有模式的订阅关系
}
链表每一个节点都是一个pubsubPattern结构:1
2
3
4struct pubsubPattern{
redisClient* client;//订阅的客户端
robj* pattern;//订阅的模式
}
发布消息时首先找到在字典中找到频道对应的客户端链表,遍历链表将消息发送给所有客户端,然后遍历模式链表,找到一个匹配的模式就将消息发送给订阅该模式的客户端(模式O(n)复杂度,非模式O(1)复杂度)。
事务
通过multi、exec、watch来实现事务。multi标志一个事务的开始,接下来的命令会进入一个队列不立即执行,等到exec命令,将队列中的命令全部按顺序执行。
watch是一个乐观锁,可以在exec执行之前,监视任意数量的数据库键,在exec执行时,当至少有一个键已经被修改过了,服务器将拒绝执行事务。数据库中有一个字典用来记录watch的信息,键是watch监视的键,值是一个链表,保存了监视这个键的客户端,当键改变之后,会查找监视这个键的客户端,打开它的REDIS_DIRTY_CAS标志,表明事务安全性已经被破坏,exec执行时首先看客户端有没有REDIS_DIRTY_CAS标志,如果有就拒绝执行事务。
事务的ACID性质,即原子性,一致性,隔离性,持久性。Redis具有原子、一致、隔离,运行在持久化模式下时具有持久性。
原子性指的是事务中的操作要么全部执行,要么全部不执行。Redis不支持回滚。
一致性指的是如果事务在执行事务前是一致的,那么在事务执行后无论事务执行成功与否数据库仍然是一致的。一致指的是数据符合数据库本身的定义和要求,没有包含非法或者无效的错误数据。
隔离性指的是多个事务并发执行,各个事务之间也不会相互影响。因为Redis总是以串行方式来执行事务,所以有隔离性。
持久性指的是执行完事务过后,结果已经被保存到硬盘里了。只有运行在AOF的always模式下才具有持久性。