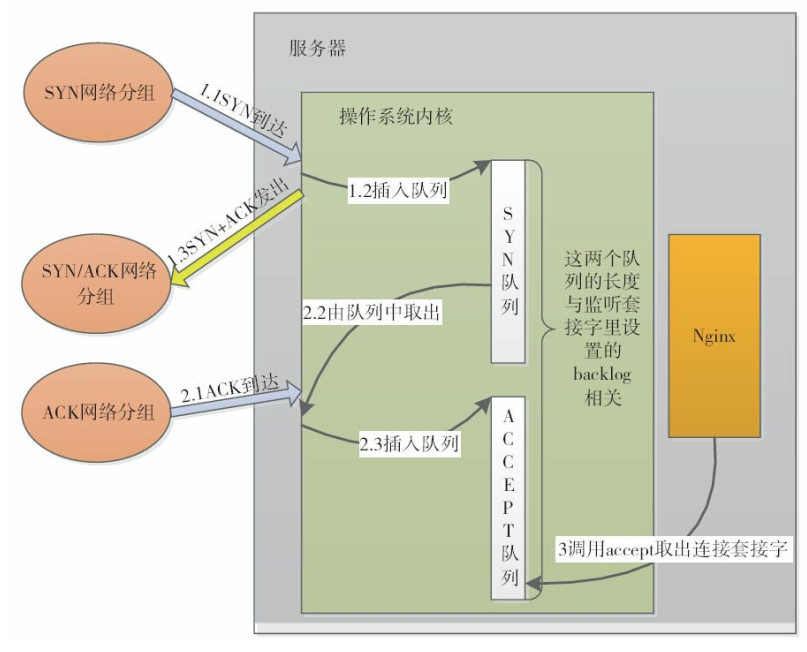
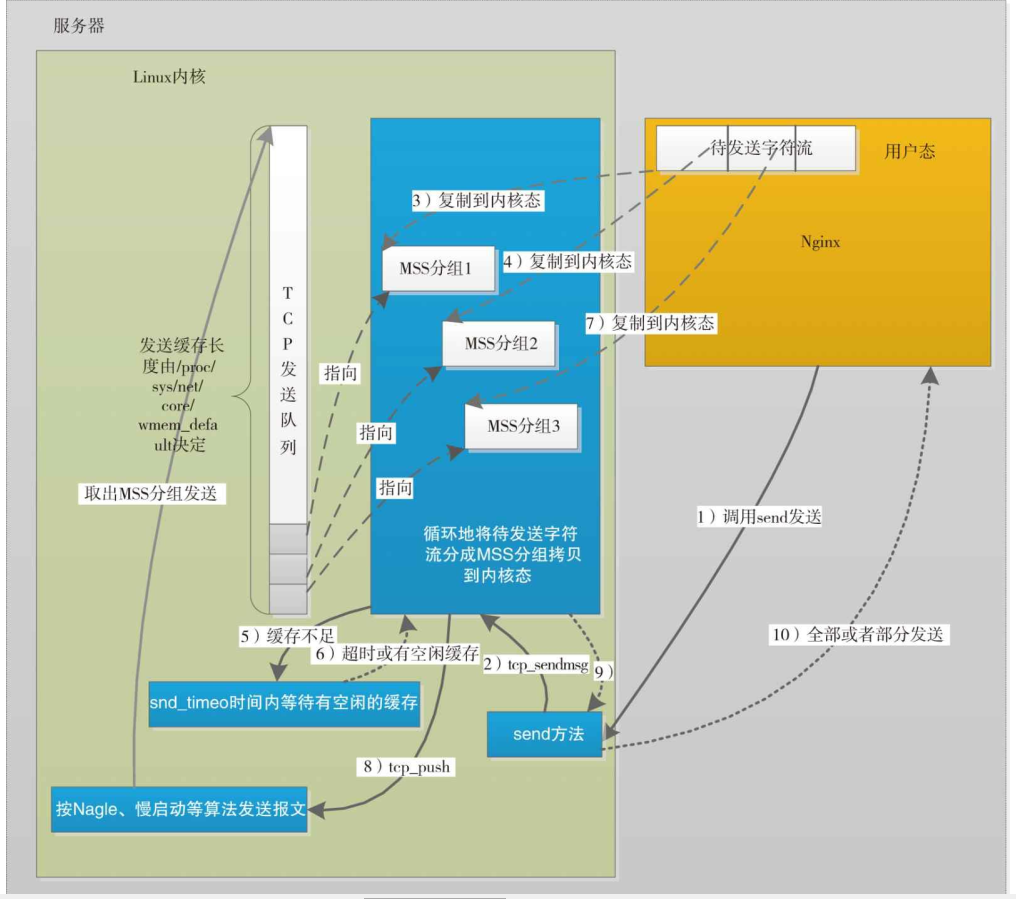
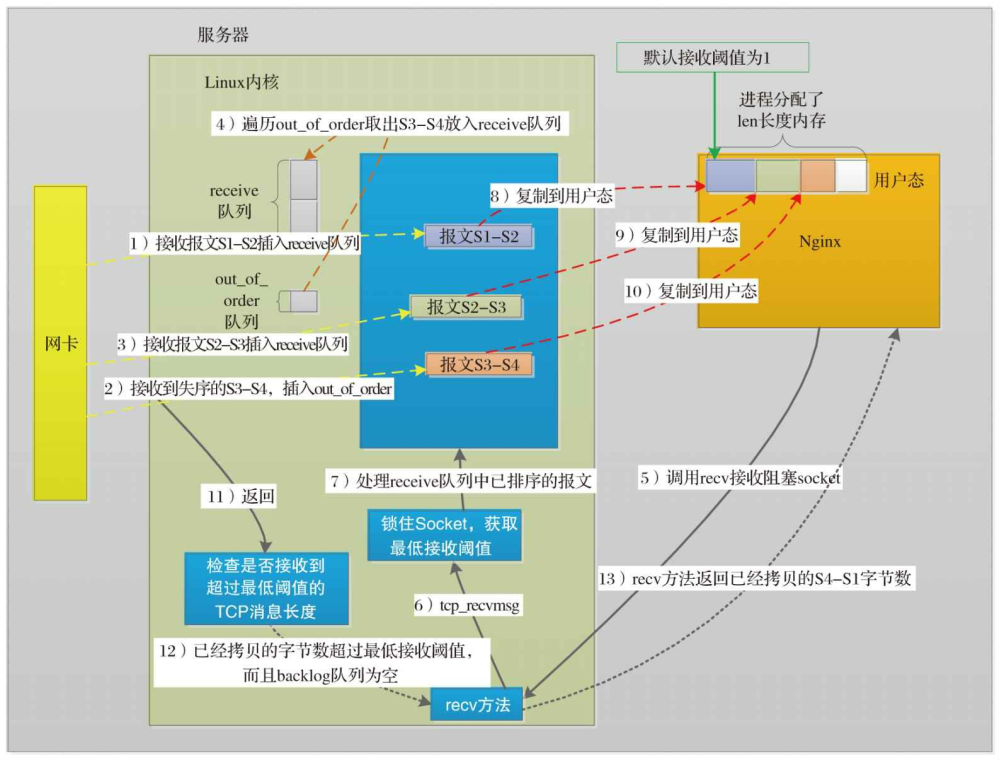
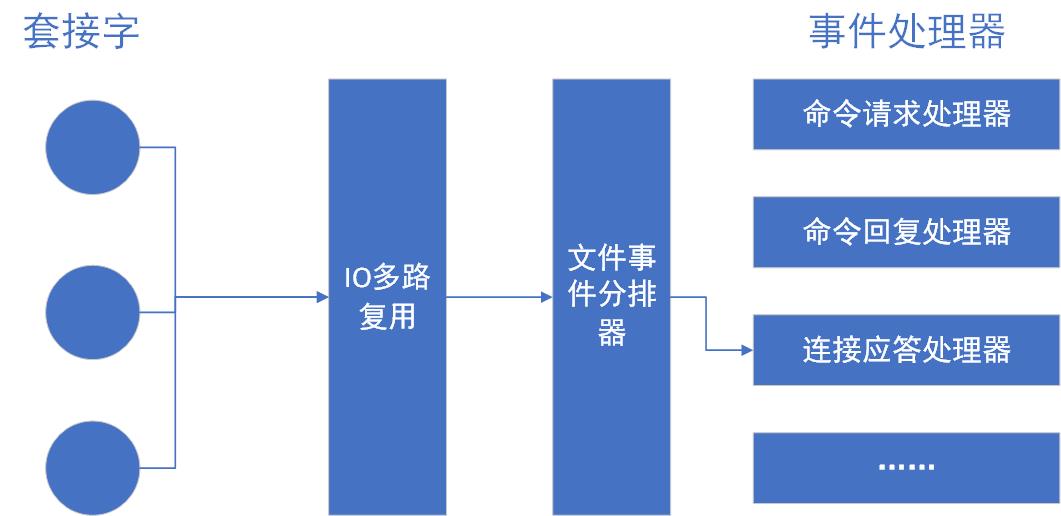
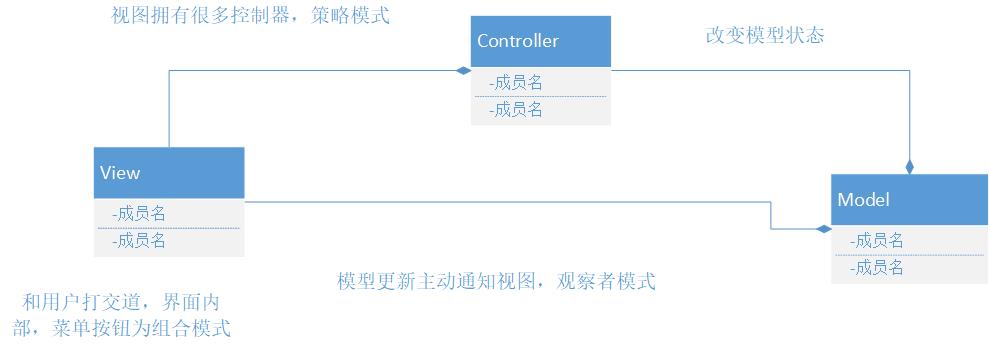
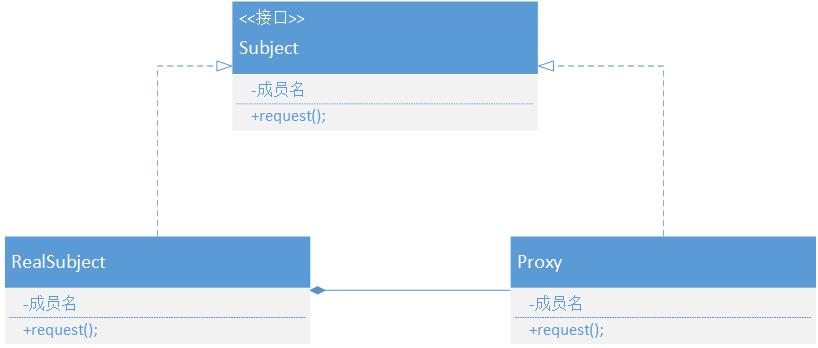
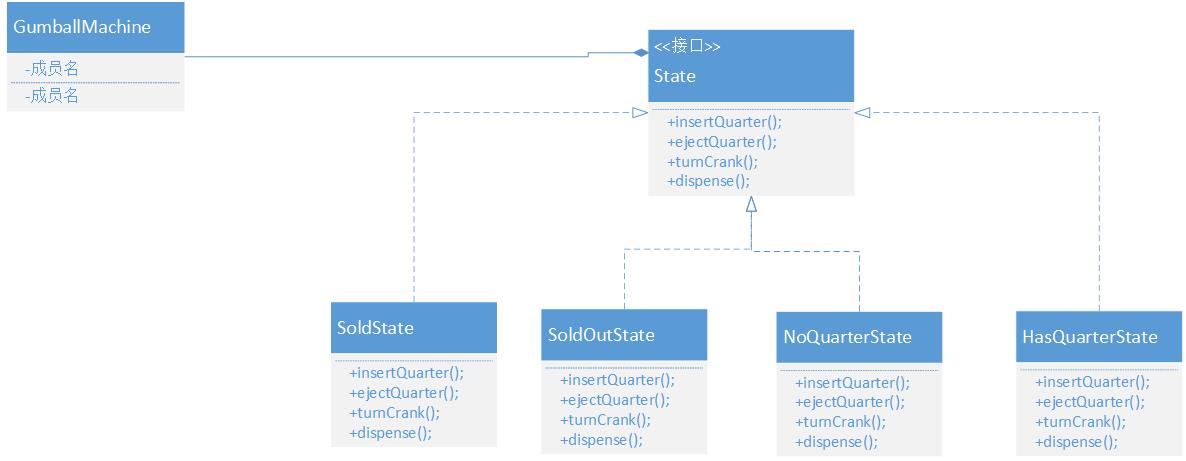
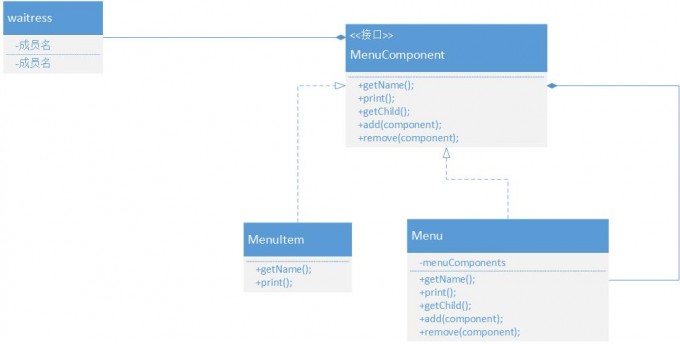
知识汇总
红黑树
规则如下:
- 每个节点不是黑色就是红色
- 根节点为黑色
- 如果节点红色,其子节点必为黑
- 任意路径到叶子节点的路径,所含黑色节点数必相同
以上规则规定了红黑树中一条路径至多是另一条路径的两倍长度。
deque
deque的实现为一系列连续的缓冲块连接在一起,通过中央map,其中每一个节点都指向一块缓冲,当要扩展时,就新开辟一个节点,申请一块缓存,指向这个缓存,当中央map满了,就会像vector一样,重新分配一块更大的空间,复制过去,释放旧空间。在向前后添加时,迭代器可能失效,但是指针不会失效,因为存放数据的缓存是不会改变的。
next_permutation
从尾端向前寻找两个相邻元素,前面的记为i,后面的记为ii,找到一组i < ii的,再从最后往前找到第一个大于i的,记为j,i和j对调,再把ii之后的所有元素倒排。
prev_permutation
从尾端向前寻找两个相邻元素,前面的记为i,后面的记为ii,找到一组i > ii的,再从最后往前找到第一个小于i的,记为j,i和j对调,再把ii之后的所有元素倒排。
partial_sort
将前n个数组成一个最大堆,遍历后面的数,和最大堆堆顶比较,如果小于堆顶就互换位置然后调整堆,如此遍历一遍,前n个数就是最小的n个数,再对前n个数进行堆排序。
sort
数据量大时采用快排,当递归到数据量小于某个阈值,改用插入排序,当递归层数过深,改用堆排序。
进程的内存结构

linux虚拟内存管理
进程布局存在于虚拟内存中,每个程序使用的内存切割成小型的、固定大小的页,任意时刻,每个进程只有部分页需要在物理内存中,当进程要访问的页不在物理内存中,发生页面错误,内核挂起进程,同时从磁盘将该页面载入内存。为了支持这个组织方式,内核为每个进程维护了一个页表,记录了每页在物理空间中的位置,若进程试图访问的位置没有页表与之对应,则会收到SIGSEGV信号。
栈帧
调用函数时,会在栈上分配一个栈帧。每个栈帧包括:函数实参和局部变量,参数是从右到左的顺序压栈,函数调用的链接信息,主要是一些寄存器,比如程序计数器,指向下一条要执行的机器指令,当函数调用另一个函数时,会在被调用函数的栈帧中保存这些寄存器的副本,以便函数返回时能将寄存器恢复原状。在函数调用的过程中,ebp和esp两个寄存器分别存放了维护这个栈的栈帧底和栈帧顶指针。
分配栈帧时,首先将ebp压栈,方便以后返回,然后将esp赋给ebp作为新的栈帧的栈底,然后esp向下扩展分配一个栈帧,返回时,将ebp赋给esp,然后ebp出栈,将出栈的ebp赋给ebp,回到上一个函数的栈帧。
内存分配
当前堆顶称为program break,brk和sbrk函数可以抬升program break,抬升后,程序可以访问新分配的地址,此时这些新内存的物理内存还没分配,第一次访问时会自动分配物理内存。
malloc和free用来在堆上分配和释放内存,一般情况下,free不降低program break,而是将这块内存添加到空闲内存列表中,供后续的malloc使用,这么做有3个原因,释放的内存位于中间而不是堆顶,因此不可能降低program break;减少了sbrk调用的次数;应用程序倾向于反复释放和分配内存。
malloc的实现:首先扫描free的空闲列表,找到尺寸大于等于要求的一块内存(first-fit或者best-fit),如果大小刚好,就返回给用户,如果较大,会对其切割,返回大小相等的,剩余的小块内存保留在空闲列表中。如果在空闲列表中找不到合适的内存,会调用sbrk分配更多的内存,为了减少sbrk的调用次数,会以比要求的大小更大的幅度来增加program break,并将超出的部分置于空闲列表。
free的实现:如何知道内存块的大小呢,在malloc分配内存时,额外分配几个字节来存放这块内存大小的整数值。当内存块置于空闲列表时,free会用内存块本身的空间来存放链表指针,一个内存块从开始的内容为:内存块长度、指向前一个内存块的指针、指向后一个内存块的指针、剩余的空闲空间。
calloc会将分配的内存初始化为0。realloc可以改变已经分配的内存块的大小,当增大时,首先尝试合并在空闲列表中紧随其后的大小合适的内存块,如果没有就分配一块新内存,将数据复制过去。
alloca在栈上分配内存,分配的内存会自动释放。
sizeof
编译时就确定下来,sizeof一个函数返回函数返回值类型大小,函数不会执行,sizeof一个表达式,表达式不会执行。
extern “C”
C++为了支持函数重载,要对函数的名称做处理,而C中不做处理,两者对函数名称的处理是不一样的,在链接阶段按照C++的命名规则去找C的函数就会出现链接错误。extern “C”告诉编译器用C的规则来链接函数。
排序
稳定排序:插入排序,冒泡排序,归并排序,基数排序
不稳定排序:堆排序,快速排序,选择排序,希尔排序
时间复杂度:
| 算法 | 最好复杂度 | 最坏复杂度 | 平均复杂度 | 空间复杂度 |
|---|---|---|---|---|
| 插入排序 | O(n) | O(n2) | O(n2) | O(1) |
| 冒泡排序 | O(n) | O(n2) | o(n2) | O(1) |
| 选择排序 | O(n2) | O(n2) | O(n2) | O(1) |
| 快速排序 | O(nlogn) | O(n2) | O(nlogn) | O(logn) |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) |
| 基数排序 | O(d(n+r)) | O(d(n+r)) | O(d(n+r)) | O(r) |
io缓冲
read或者write不会直接操作磁盘文件,仅仅在用户空间和内核缓冲区高速缓存之间复制数据,内核会在后续的某个时间缓冲区中的数据同步到文件中,也就是说系统调用和磁盘操作并不同步。这样的设计让read和write速度更快,因为不用等待磁盘操作,而且也可以减少磁盘传输数据的次数。fsync会强制把缓冲区中的数据刷新到磁盘中,open的时候指定O_SYNC标志也可以让后续的写入立即同步。
stdio库也有缓冲区,可以用setvbuf或者fflush强制刷新,这个缓冲区在用户空间,而io的缓冲区在内核。
open时指定O_DIRECT可以在用户空间和磁盘文件直接进行IO。
文件描述符和流可以互相转换,fileno将流转成描述符,fdopen将描述符转成流。
i-node
对于系统上的每个文件,文件系统的i-node表会包含一个i-node,ls -li现实的第一列就是i-node。
i-node维护了一些信息:
- 文件类型
- 文件属主
- 文件属组
- 3类用户的访问权限
- 3个时间戳,最后访问时间,最后修改时间,文件状态的最后改变时间
- 指向文件的硬链接数量
- 文件大小
- 分配给文件的块数,512字节块为单位,文件块中包含了文件内容
链接
硬链接是指多个文件指向同一个i-node,软链接是指一个文件的内容是另一个文件的名称。i-node会维护一个计数,每有一个硬链接计数就增加,当计数为0时,系统会释放i-node中的数据块。
i-node中不包含文件名,目录会列出文件名和对应i-node的一个表格。
SIGSEGV
当应用程序对内存的引用无效时,会产生该信号。可能是因为要引用的页不存在,或者试图修改只读内存,或者用户试图访问内核部分内存,C语言中往往是指针包含的地址错误。
fork
子进程返回0,父进程返回子进程的进程id,错误返回-1。子进程拥有父进程数据段、堆、栈的拷贝,但是采用写时复制的手法,修改时才拷贝,和父进程共享代码段,共享文件描述符。
vfork是为fork之后立刻调用exec专门设计的,他不会拷贝父进程的内存,而且在子进程执行exec之前,父进程会暂停执行。vfork保证子进程优先于父进程得到调度。
通常只有一个进程调用exit,其他子进程调用_exit,exit会刷新stdio缓冲区。
父进程使用waitpid回收退出的子进程,常常安装SIGCHLD的信号处理器,在处理器函数中循环调用waitpid,使用WNOHANG标志非阻塞地回收子进程。
clone也可以创建进程,不同的是,clone可以指定子进程的起始函数,而且对父子之间的共享属性有更精确的控制,主要用于线程库的实现。fork、vfork、clone都是由kernel/fork.c中的do_fork实现的。
pthread
每个线程都有属于自己的errno。线程的一些函数:
- pthread_create:创建线程
- pthread_exit:退出线程,相当于在线程函数里面return
- pthread_join:连接线程,相当于线程版的waitpid,回收线程资源
- pthread_detach:线程分离,不需要手动进行join,但是当主线程退出时,该线程也会退出
线程的优点:
- 线程间共享数据很简单,相比之下,进程间共享数据需要ipc
- 线程创建速度比进程快,上下文切换的开销比进程小
线程的缺点:
- 确保线程安全
- 某个线程中的bug可能会危及进程内的所有线程,而进程之间空间不共享,隔离更彻底
- 每个线程都适用宿主进程的虚拟空间,空间是有限的,当分配大量线程时就会受到限制,而每个进程可以使用全部有效的虚拟内存
除此之外,多线程程序应该避免使用信号,所有线程运行同一个程序,而多进程可以运行不同的程序。
信号量与互斥量
只有锁住互斥量的线程能对它解锁,而一个线程可以递增一个被另一个线程锁住的信号量。
shutdown
可以实现半关闭,关闭写端用得最多。shutdown可以立即关闭套接字通道,而close只是将引用计数减1。shutdown不会关闭描述符,只能用close来关闭。
sendfile
又称零拷贝传输,把文件直接在内核中发送到socket的发送缓冲区中,省去了内核空间和用户空间之间的拷贝,只能用于将文件传输给socket。
time_wait
有两个作用,一是实现可靠的连接终止,二是让老的重复报文段在网络中过期消失。
如果关闭阶段最后的ack服务端没有收到,服务端会重发fin,这时若客户端关闭则无法重新发送ack,连接就得不到关闭,反而会发送一个rst作为响应,这个rst会解释为一个错误。通常维持2MSL时间,一个MSL是ack发送的时间,另一个MSL是fin重新发送的时间。
考虑连接关闭后有个新连接用同样的端口建立起来,tcp协议采用的重传算法可能产生重复的报文,这些老的重复的报文可能在连接关闭后才到达服务端,这时候服务端可能把这个报文误认为是新的连接发送的,为了避免这种情况,time_wait状态是必须的。
在这期间,端口被占用,服务器不能立刻绑定该端口,可以设置tcp的选项SO_REUSEADDR,即可关闭服务器后立刻绑定同一个端口,同时仍然允许time_wait状态生效。
udp的优势
udp不需要建立连接,因此传送单条信息开销较小,且速度更快。DNS就是应用udp的例子。udp可以进行广播和组播。有些应用不需要tcp的可靠性也能在接受范围内,相反,tcp的超市重传造成的延时是不能接受的,比如视频流,这样的应用udp更合适。
select和poll的问题
- 每次调用后必须检查所有的文件描述符
- 每次调用都要将相应的数据结构从用户空间拷贝到内核,内核修改后再拷贝到用户空间,非常耗费cpu
epoll的优势
- 不需要每次传递要监视的描述符到内核,内核会维护所有的要监视的描述符
- 返回的是已经就绪的描述符集合,不需要再对所有描述符遍历一遍
epoll的使用场景是需要同时监视大量描述符,但是大部分处于空闲状态,只有少数处于就绪状态。
边缘触发
EPOLLET通常和非阻塞套接字配合使用。使用et触发,一个事件只会得到一次通知,所以必须在这次通知将其处理完毕,不断执行io直到返回eagain。
当一个描述符上有大量io时,如果这时尝试将所有输入都读取,其他描述符可能会处于饥饿状态得不到处理,可以维护一个列表,列表中存放已经就绪的文件描述符,不立刻进行io,epoll调用完之后,再对列表中的描述符进行一定限度的io,直到有返回EAGAIN就可以将这个描述符从列表中删除了。
http1.0、1.1、2.0
- http1.0和1.1:1.1默认支持长连接,1.0需要设置keep-alive字段才行;1.1支持host域,1.0不支持;1.1可以只发送头部字段,等到收到100再继续发送消息体,若收到401就不必发送消息体,节约了带宽,1.0不支持,此外1.1还支持发送部分内容。
- http1.1和2.0:2.0支持多路复用,一个连接并发处理多个请求,1.1不支持;2.0支持对头部进行HPACK压缩,体积小了传输速度更快,1.1不支持;2.0支持服务器推送,当客户端请求时,服务器会把客户端需要的资源缓存到客户端本地,下次客户端就可以直接从本地加载,不需要通过网络。
https
由于http是明文传输,故数据可能被抓包篡改,https=http+认证+加密。
https建立过程:
脏读、不可重复读、丢失更新
- 脏读:事务对缓冲池中数据的修改,并且没有提交。一个事务可以读取到另一个事务尚未提交的数据。
- 不可重复读:在一个事务中,多次读取一个集合,另一个事务也访问该集合并作了一些修改,那么第一个事务两次读取的数据可能是不一样的。脏读是读到了未提交的数据,不可重复读是读到了已经提交的数据。
- 丢失更新:一个事务的更新会被另一个事务的更新所覆盖,导致数据不一致。
乐观锁、悲观锁
乐观锁:总是认为不会产生并发问题,每次去取数据的时候总认为不会有其他线程对数据进行修改,因此不会上锁,但是在更新时会判断其他线程在这之前有没有对数据进行修改,一般会使用版本号机制或CAS操作实现。
悲观锁:总是假设最坏的情况,每次取数据时都认为其他线程会修改,所以都会加锁(读锁、写锁、行锁等),当其他线程想要访问数据时,都需要阻塞挂起。可以依靠数据库实现,如行锁、读锁和写锁等,都是在操作之前加锁。
并查集
1 | int parent[N]; |
gc算法
- 引用计数法:
给对象添加一个引用计数器,每过一个引用计数器值就+1,少一个引用就-1。当它的引用变为0时,该对象就不能再被使用。它的实现简单,但是不能解决互相循环引用的问题。 - 根搜索算法:
以一系列叫“GC Roots”的对象为起点开始向下搜索,走过的路径称为引用链(Reference Chain),当一个对象没有和任何引用链相连时,证明此对象是不可用的,用图论的说法是不可达的。那么它就会被判定为是可回收的对象。 - 标记-清除算法
这是一个非常基本的GC算法,它是现代GC算法的思想基础,分为标记和清除两个阶段:先把所有活动的对象标记出来,然后把没有被标记的对象统一清除掉。但是它有两个问题,一是效率问题,两个过程的效率都不高。二是空间问题,清除之后会产生大量不连续的内存。 - 标记整理算法
标记整理算法适用于存活对象较多的场合,它的标记阶段和标记-清除算法中的一样。整理阶段是将所有存活的对象压缩到内存的一端,之后清理边界外所有的空间。它的效率也不高。
蓄水池抽样
从n个对象中随机取一个对象,每个对象被取到的概率为1/n,假设不知道n的值,或者n非常大,无法直接rand()%n。解决方法是总是选择第一个对象,以1/2的概率选择第二个,以1/3的概率选择第三个,以此类推,以1/m的概率选择第m个对象。当该过程结束时,每一个对象具有相同的选中概率,即1/n,证明如下。
第m个对象最终被选中的概率P=选择m的概率*其后面所有对象不被选择的概率,即
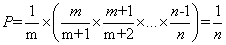
代码:1
2
3
4
5
6
7
8
9
10
11int cnt = 1;
object choose;
for(object o:objs){
if(cnt == 0)
choose = o;
else{
if(rand()%cnt == 0)
choose = o;
}
++cnt;
}
gdb原理
通过ptrace系统调用实现,ptrace可以让父进程观察子进程的运行,gdb run一个程序时,首先fork一个子进程,在子进程调用ptrace,然后exec加载指定的程序运行。
gdb调试建立在信号的基础上,设置断点时,找到该行代码的具体地址,向该地址写入断点指令,INT3,程序运行到这里会触发SIGTRAP信号,然后根据目标程序当前停止的位置在gdb维护的断点链表中查询,若存在,则可判定为命中断点。gdb暂停目标程序运行的方法是想起发送SIGSTOP信号。
如果一个进程CPU占用太大,如何定位和调试这个进程?
用top命令找到最占CPU的进程,使用pstack跟踪进程栈,此命令允许使用的唯一选项是要检查的进程的PID,使用top命令查看指定进程最耗CPU的线程,top -H -p pid,如果想查看具体的原因,如现场的函数中变量等的数值等,就要使用的GDB的实时调试功能,gdb attach pid。
new和malloc
linux中,对于一个已经动态编译后的文件,怎么查找出它用了哪些动态库?
ldd。
Linux共享库的搜索路径先后顺序
1、编译目标代码时指定的动态库搜索路径:在编译的时候指定-Wl,-rpath=路径
2、环境变量LD_LIBRARY_PATH指定的动态库搜索路径
3、配置文件/etc/ld.so.conf中指定的动态库搜索路径
4、默认的动态库搜索路径/lib
5、默认的动态库搜索路径 /usr/lib
kmp
1 | vector<int> getNext(const string& pattern){ |
洗牌算法
1 | void shuffle(vector<int>& num){ |